1. Clickhouse的简介
ClickHouse是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),使用 C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
2. Clickhouse的列式存储
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
在传统的行式数据库系统中,数据按如下顺序存储:
| Row | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016/5/18 5:19 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016/5/18 8:10 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016/5/18 7:38 |
| #N | … | … | … | … | … |
处于同一行中的数据总是被物理的存储在一起。常见的行式数据库系统有: MySQL、Postgres、oracle和MS SQL Server。
在列式数据库系统中,数据按如下的顺序存储:
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
该示例中只展示了数据在列式数据库中数据的排列顺序。对于存储而言,列式数据库总是将同一列的数据存储在一起,不同列的数据也总是分开存储。
常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
不同的存储方式适合不同的场景,这里的查询场景包括: 进行了哪些查询,多久查询一次以及各类查询的比例; 每种查询读取多少数据————行、列和字节;读取数据和写入数据之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
系统负载越高,根据使用场景进行定制化就越重要,并且定制将会变的越精细。没有一个系统同样适用于明显不同的场景。如果系统适用于广泛的场景,在负载高的情况下,所有的场景可以会被公平但低效处理,或者高效处理一小部分场景。
列式储存的好处:
– 对于列的聚合,计数,求和等统计操作原因优于行式存储。
– 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
– 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的发挥空间。
3. Clickhouse的SQL引擎和向量化
支持SQL
ClickHouse支持基于SQL的声明式查询语言,该语言大部分情况下是与SQL标准兼容的。 支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询。 不支持窗口函数和相关子查询。
向量引擎
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。
4. Clickhouse的吞吐能力
ClickHouse 采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类 LSM tree的结构,ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,在后台compaction 时也是多个段 merge sort 后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在 HDD 上也有着优异的写入性能。
官方公开 benchmark 测试显示能够达到 50MB-200MB/s 的写入吞吐能力,按照每行100Byte 估算,大约相当于 50W-200W 条/s 的写入速度。
5. 数据分区和线程级并行
ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index granularity(索引粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
所以,ClickHouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务,ClickHouse 并不是强项。
6. 性能数据
- 数据压缩
数据压缩方面,Sparkql、Impala、Presto均采用的是hive元数据,hive数据100G上传之后显示为96.3G(.dat数据格式),压缩比0.963;hawq压缩后数据大小为68.2G(.dat格式),压缩比:0.682;clickhouse采用自己默认格式42G;greenplum未使用压缩,数据存储大小为98G。 - 性能测试
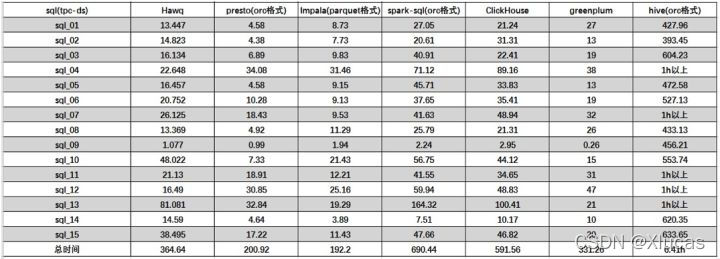
多表关联查询
单表查询性能
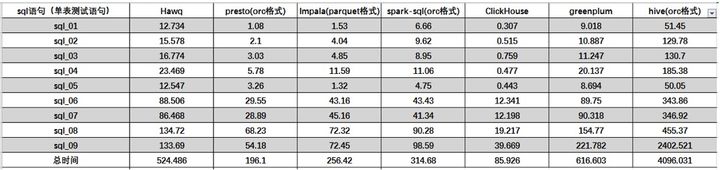
ClickHouse 作为目前所有开源MPP计算框架中计算速度最快的,它在做多列的表,同时行数很多的表的查询时,性能是很让人兴奋的,但是在做多表的join时,它的性能是不如单宽表查询的。性能测试结果表明ClickHouse在单表查询方面表现出很大的性能优势,但是在多表查询中性能却比较差,不如presto和impala、hawq的效果好。
更多内容关注公众号
